Common Makefile Interface
- 11 minutes read - 2135 words[_build] render=“always” list=“never” publishResources=“true”
He had eyes all around his head and spoke magic words that could turn the day sky into night sky and night sky into day sky…
— Seamingly unrelated opening quote
Rationale
SDLC has numerous definitions and ways to dissect it, let’s asume the following for the sake of an argument:

It’s obviously not that simple - the model expands across time with numerous sub-dependencies etc.:
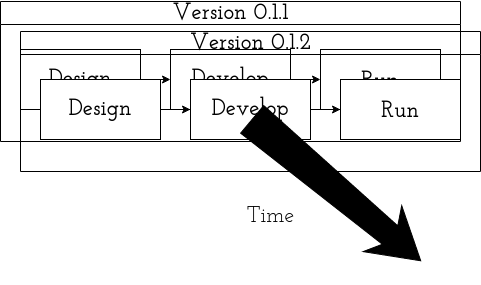
Interfaces
But that’s not the part of SDLC I want to talk about today! I’m more interested in how the pieces fit togheter. The interfaces. So an example could look like this:

If the concept above doesn’t cause you to shake and tremble in search of a comment section (spoiler alert: there isn’t one) to begin a rant - feel free to skip the “note:” sections
Note: what do I mean by Docker
Obviously no SDLC is the same, though many are alike. You may doodle on a board(white or black), piece of paper, tablet or directly on the walls (deranged Silicon Valley genius style!). You may use cri-o, podman, rkt (it this even alive? o.0) or something that doesn’t yet exist at the time of writting. My point: your respective parts of SDLC looks somewhat like this or at least you wish they were.
Note: but embedded!
Fully agreed, this post is targeted mostly at ~backend ~application ~developers. Turns out they’re not that different from you, dear embedder. You may still learn a lot from this. For now, consider “Docker container image” to be what it truly is - just a bunch of arranged bytes.
The gap between your things
There is a part of the process though that misses out on such formalization and convergence. See this:

Various developers (having different machines, potentially different OSes), devops (think: smart, but not invested in that particullar project) and a ~technical manager (think: invested in a project but with little technical expertise - can ran commands from tutorial, but won’t fix errors or quickly flopnax the ropjar using rilkef). Someone is bound to ask:
How do you actually run this thing?
And it will turn out that the README is outdated. The wiki page is missing a dependency. For unit tests. The database needs migration. You’ve confused the order of steps in the instruction. Do you start over? Is the process idempotent?
I’ve seen things. Particularly this. Too. Many. Times.
At various companies, be it big or small. Developers with or without CS degree . This is a serious problem that I belived we (the people) are capable of solving.
The mess
Currently the gap is filled by development specific tools, like yarn for SPAs (or is it npm now?), maven for Java apps and cargo for Rust. This causes cognitive overhead and prevents standardization.
The problem calls for:
- technology agnostic interface (so: one tool for JS, Java, Rust…)
- interoperability with whatever is used underneath
- self-documenting solution
Furthermore, following standardized features would be required:
- single (yet tweakable) way of getting the app started with sensible defaults
- running unit-tests
- running static analysis
- spitting out the container
- building the app (if applicable)
Along comes [GNU]Make!
Remember Make? With a GNU flavour! Turns out that while it’s quite decent a compiling C, but that’s not the point - it can be used as a sensible enough-cross platform task runner2.
The .PHONY: directive can be used for defining non-file targets.
.PHONY: run setup
run: setup ## run the app
@echo "Not implemented"; false
setup:
For those unfamilliar with Make: Upon make run this will execute setup (which is empty) and then run (which will output “Not implemented” and fail). You can obviously put targets that are actual files into the mix.
Small idea
.PHONY: run lint test container build env-up env-down env-recreate
A defined set of targets for actions that are commonly done with software. Independent of the undeylaying technology, yet interoprable with any concrete task runner (like the aformentioned yarn). It’s not about replacement - those tools work just fine. It’s about adding another layer.
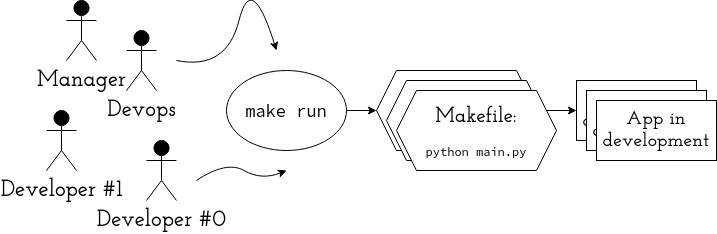
Imagine all the agents (or stakeholders… or just people) interacting with any project in a well-defined standardized manner. Obviously you may want to tweak the configuration at some point - use different database setup, etc. But there will come a time for anyone invested in the project to just get the app running. For many it will their last encounter with that particullar piece of software.
A devops can be in a hurry to fix a bug, but the project in question is a dependency. She need’s to run it with debug tracing enabled. make run, then a quick Makefile examination to figure out which particular flag to turn. Done!
I’ll leave other scenarios like:
- a manager (technical enough to ran few shell commands) wants to quickly see the very latest pre-staging version
- an intern is being onboarded into the company
- open source
as an excercise for the reader.
Note on prior art
It’s not like I woke up some day and decided to do things this way. This a reflection and formalization on what I’ve been doing myself for the last ~2 years while working for 3 distinct employers3.
Furthermore, Make is a mature tool, first appeared in 1976, so around 40+ years ago3. Originated to solve the problem of forgetting to recompile (remember the stuff about C?). It’s readily avaible (and might be even preinstalled) on any unix-like platoform. Makefiles are here to stay.
There’s a number of friends and strangers already using them!
Case studiy - Digitalocean Token Scoper
This project was a spur-of-the-moment product of me having a problem and the desire to finally do something in Golang. It’s a real world project, running in production.
Companions
The examples above heavily utilize other tools. They’re not the point of this blogpost and deserve an articule in their own right, however it wouldn’t be complete without at least pointing out how they all work together. It’s not by any means required by the Common Makefile Interface, but it’s the best way to do things that I’m aware of.
Nix
Nix. Like… where do I even start… For the purpose of what’s already said Nix provides reproducible environments in a sensible (so that it’s actually reproducible and you don’t cure that much while setting it up) cross-plaform cross-plaform manner. I say ‘cross-plaform’ twice, since it works with different development technologies (Node, Haskell, Go, etc.) as well as host OSes (Mac, GNU/Linux, WSL).
You can also use Nix to build Docker images and it’s quite decent at it (FROM scratch builds, heavily leaveraging image layers). And I’ll speak of it in this post no more.
I’ll be having a talk about Nix at this year’s Cebula Camp [it’ll likely be recorded!] and there’s tons of recordings from other conferences to introduce you to the subject properly.
Direnv
Direnv along with direnv-nix put the ‘seam’ in ‘seamless experiance’ - you don’t have to type nix-shell - this tool will execute certain commands automatically upon entering a directory. Additionally it provides an additional level of caching so that no expression is evaluated twice.
Entr
Entr, though not touched on explicitly is still worth mentioning -> it runs commands upon file changes. So that:
ls main.py | entr -c make test
will run unittest every time main.py changes. It can be utilized to provide an insanely convenient TDD loop by running two panes - one with the editor and the other entr.
Misc
Self-documentation and tooling culture
The best documentation is self-explanatory code. The second best is self-documenting code. It is possible for a make to do reflection on itself and with the folowing piece of awk present it sensibly:
help: ## print this message
@grep -E '^[a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) \
| awk 'BEGIN {FS = ":.*?## "};
{printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
.DEFAULT_GOAL := help
with the result looking like4:
run run the app
build create artifact
lint run static analysis
test run all tests
...
help print this message
This enables to recover from standard deviations quickly (so that if you’re hell bent on calling run for example launch it’s less of a problem), accounts for old-timers accustomed to make configure; make; make install as well as emables discoverability of project-specific functionality not addressed by the standard.
Speaking of dedicated targets - in my opinion the presented appraroch encourages engineers to commit useful hacks to the repository. So instead of creating an oddly named script in arbitrary nested in the project file structure (better) or not subbmitting it at all (worse) there’s now a place for storing those scripts (which are really ad-hoc specialized tooling) in a manner that’s discoverable, convinient to run and document.
It won’t in itself transform your company into an agile-driven non-nonsense KPI-oriented cloud enterprise on it’s own, yet people behaviour is a function of their environment.
A generic example of the above could be the TODOfinder I’ve made:
todo: ## list all TODOs in the project
git grep -I --line-number TODO \
| grep -v 'list all TODOs in the project' \
| grep TODO
Did I mentioned that it’s much easier to keep those scripts up to date and prevent wiki-rot when the key scripts are kept next to source code and are ran daily?
Additionally, the make is flexible enough that the scripts may be embedded into the Makefile itself. Plz no abuse. It can save some anoying arguments passing though.
.ONESHELL:
interact: ## helper process to run predefined inputs
@while read line
do
case $$line in
p*)
curl ... -H "Authorization: Bearer $(CLIENT_SECRET)"...
;;
f*)
curl http://localhost:$(PORT)...
;;
*)
;;
esac
done
In the example above I’m using ONESHELL directive to embedd an interactive shell scripts that heavily depends on Makefile varaibles.
Not starting from SCRATCH!
Additional things to keep in mind is that most projects are somehow simillar, especially at their initial stages. So most new projects READMEs will tell you how to install dependencies and run the app, maybe with some companion services (think datastore). A CI woudl see if the app buils, passes linters and some basic unit tests. Of course in due time idiosyncracies will grow to the point were they require an explicit presence as a separate CI step (imgae a hierarchy of integration test that run with varying frequency).
But in the begging the basic steps are de-facto the same. And since we’ve abstracted the specific meaing of those basic steps a README can be prepared against them as well as a CI for a particular platform, since it’s make buil&& make lint && make test in whatever is the latest flavour of YAML. Read on to see, how some of it might look like!
Glue - intialization hook
I may be overstating the significance of this part, but I find it insanely cool that I can standardize the hook for one time setup. The need was rooted in security model of direnv - basically you have to explicitly enable it initially and every time the code changes (you should read it as well).
Here it is - in all it’s glory:
init: ## one time setup
direnv allow .
I’ve modified it from that form only once so far - to hide the initial direnv warrning (the one that says “direnv is disabled - run such and such to enable”):
init: ## one time setup
-mv --no-clobber _.envrc .envrc 2>/dev/null
direnv allow .
Turns out the presence of said warning was confusing some of the devs I was working with.
Call to action!
I strongly belive that it’s the case of agreeing on something rather than bikesheding (xkcd pic rel)

Implement
- try starting a new project from this template
- just give it a shot - in whatever shape or form!
Contribute
- commit to the standard and tooling
- spread the word - share this article, mention it to your friends, hell, give a talk!
- talk to me - tell me it’s stupid and why it’ll fail miserably, utter a tale of grand sucess, weave a story full of mystery, betrayal and romance. Or just drop a hint what could be improved in your opinion. Either through Github issues or email me (it’s my first name, at sign, this domain, all lowercase - suck it, bots).
Footnotes
TODO - https://news.ycombinator.com/item?id=30137254 TODO - https://news.ycombinator.com/item?id=30671572 )https://news.ycombinator.com/item?id=35936665 TODO - https://nullprogram.com/blog/2017/08/20/ <- Makefile target conventions TODO potential testimony - https://rosszurowski.com/log/2022/makefiles https://bultrowicz.com/continous_validation_with_make_and_entr/ TODO - https://www.bitecode.dev/p/doit-the-goodest-python-task-runner also: just TODO - what do I even think of this? - https://redo.readthedocs.io/en/latest/ uwaga Pusia: i przez makefile nie przekażesz łatwo specjalnych flag konfiguracyjnych, które chcesz sobie pozmieniać - dopisać
the graph and the one below bears an uncanny simillarity to the meaning of meaning ↩︎
here are some tutorials ↩︎
welp, it displays that in color, though I don’t feel like reporducing that on my blog ↩︎